Yet Another Graph-Search Based Planning Library (YAGSBPL)
Dec 30, 2010
A template-based C++ library for large-scale graph search and planning
Graph search algorithms like Dijkstra's, A* and weighted A* have been implemented in several C++ libraries. Some of the well-known libraries like STL, BOOST and LEMON have quite nice graph search algorithm implementations. Another very important and technical implementation is the SBPL by Maxim Likhachev from CMU (http://www.cs.cmu.edu/~maxim/software.html). While I did use many of these in multiple occasions with great results, I still ended up writing a library of my own because of certain additional requirements in my applications, which eventually ended up evolving into a very generic graph search & planning library. I created this library hoping to achieve a good balance between speed, efficiency, ease of use and versatility. Hopefully you'll find it useful.
Download YAGSBPL library: yagsbpl-2.1.zip (Licensed under GNU-GPL)
Or, download it from Google Code: http://code.google.com/p/yagsbpl/
Requirements: C++ compiler with STL
Installation: Read Installation and Compiling in the documentation below.
For a quick start:
Download basic example programs: yagsbpl-2.x_basic-examples.zip
Requirements: C++ compiler with STL and YAGSBPL library
This collection of programs demonstrate the 3 different ways of describing a graph (as detailed in the tutorial below):
i. The easiest way using global function pointers, ii. by inheriting and redefining virtual functions, iii. by using function container.
Download example programs with visualization: yagsbpl-2.x_opengl-examples.zip
Requirements: C++ compiler, OpenCV library (including 'cvaux' and 'highgui') and YAGSBPL library
These example program illustrates the event handlers introduced in v2.0, and planning with topological constraints as discussed in http://goo.gl/kbL5V.
Citing the library:
Suggested citation format: Subhrajit Bhattacharya (2013) "YAGSBPL: A template-based C++ library for large-scale graph search and planning". Available at http://subhrajit.net/index.php?WPage=yagsbpl
Bibtex entry:
@misc{yagsbpl,
title = {YAGSBPL: A template-based C++ library for large-scale graph search and planning},
author = {Subhrajit Bhattacharya},
note = {Available at http://subhrajit.net/index.php?WPage=yagsbpl },
url = { http://subhrajit.net/index.php?WPage=yagsbpl },
year = {2013}
}
YAGSBPL:
A template-based C++ library for graph search and planning
Contents
Features
The primary considerations behind developing the library were:
- Dynamic graph construction: One shouldn't need to construct and store a complete graph before starting the search/planning process. The graph is constructed and states are expanded on the fly and as required. This makes it highly suitable for use with RRT-like graph construction. (This is an already-existing feature in SBPL)
- Should be easy to use: Specifically, defining a graph, even the complex ones, should be very easy to do. This was one of the most important motivating factor behind writing this library. YAGSBPL is a template-based library. Hence defining new arbitrary node-types, cost types, etc. is made easy. For graph connectivity, node accessibility tests, etc, pointers to user-defined functions can be used, which makes defining the graph structure very easy, yet highly flexible.
- Should be fast & efficient: Any graph search without the global knowledge of the graph from before typically needs a hash table for maintaining and creating the graph nodes, as well as needs an efficient heap for ordering the nodes in the open list. These are the components that tend to slow down the search processes. YAGSBPL uses an efficient hash table as well as an efficient "keyed heap" implementation that is fast and scales well with problem size. For example in the sample programs, with integer coordinates for nodes but floating point cost as well as cost function needing to compute floating point operations online, and an average degree of the graph being 8, YAGSBPL can expand more than 50,000 nodes in the graph in about 0.8 seconds.
- Multiple start and goals: In the graph search we should be able to have multiple start coordinates (seeds), store trajectories intermediately, and have multiple possible goals (or complex ways of defining possible goal nodes). This was one of the requirements in my applications because of which I started to write this library in the first place.
YAGSBPL supports:
- Directed graphs with complex cost functions.
- Dynamic graph construction.
- Arbitrary graph node type declaration.
- Arbitrary edge cost type declaration.
- Intermediate storage of paths during graph search.
- Multiple goals (or goal manifold) that determine when to stop search.
- Multiple seed nodes.
- Event handling.
- Ability to write new planners with much ease. Comes with a weighted A* (that includes Dijkstra's and normal A*) planner by default.
So without any further delay, we dive right into some tutorials on YAGSBPL.
BASIC USE
For any search problem, YAGSBPL needs to have two primary components: A graph description, and a planner. These two are bound together by the YAGSBPL-base library. By default YAGSBPL comes with a weighted A* planner (which includes Dijkstra's and normal A*). So from an user perspective the first thing you would probably like to do is create a graph and use the default planner to search in it.
Creating a Graph:
Creating a graph is a two-step process:
- Define a node type (a C++ class) with the
operator==overloaded for it. - Define functions that describe the graph: which nodes are accessible, define the connectivity of the graph, define costs & heuristics, mention the start & goal nodes, etc.
Thus, in your code, say "mygraphsearch.cpp", you would probably start with something like,
#include <stdio.h>
// YAGSBPL libraries
#include "yagsbpl_base.h"
#include "planners/A_star.h"
// A node of the graph
class myNode
{
public:
int x, y; // Profiling observation: integer coordinates,
// hence operator==, makes the search significantly
// faster (almost 10 folds than double)
bool operator==(const myNode& n) { return (x==n.x && y==n.y); }
// This must be defined for the node class
};
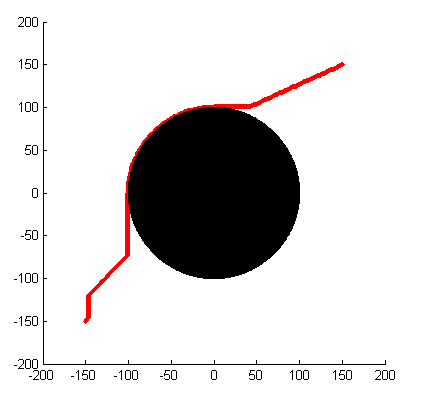
Illustration of example followed in this tutorial.
Brief description of the node type in the example above: The above example node type defines discretization of an X-Y plane with a graph node placed at every integer coordinates. The adjacent figure illustrates the scenario of the example that we will follow next: a discretized plane from -200 to 200 in both X and Y directions, and with an obstacle of radius 100 at the center. Note that we have overloaded the '==' operator for the node type. This operator will tell the planner if two nodes are the same. This is the only thing that the planner needs out of a node type. Other than that the member variables of the node (x and y in this case) can be anything arbitrary.
Once a node is defined, it's time to define the connectivity of the graph, which nodes are accessible, etc. For these YAGSBPL provides the template class "GenericSearchGraphDescriptor" meant to describe the structure of a graph.
The members of the class are described below. (skip to example instead)
Snippet from YAGSBPL library:
class GenericSearchGraphDescriptor
{
public:
// Primary functions describing the graph
int (*getHashBin_fp)(NodeType& n); // This MUST be provided.
bool (*isAccessible_fp)(NodeType& n); // optional
void (*getSuccessors_fp)(NodeType& n, std::vector<NodeType>* s,
std::vector<CostType>* c); // s: successors, c: transition costs
void (*getPredecessors_fp)(NodeType& n, std::vector<NodeType>* s,
std::vector<CostType>* c); // May not be used by all planners
CostType (*getHeuristics_fp)(NodeType& n1, NodeType& n2); // optional
bool (*storePath_fp)(NodeType& n); // optional
bool (*stopSearch_fp)(NodeType& n); // optional if "TargetNode"
// is provided.
// Primary variables
int hashTableSize; // Number of hash bins. This MUST be provided.
// "getHashBin" must return a value between
// 0 and hashTableSize-1
// At least one of SeedNodes or SeedNode should be set.
NodeType SeedNode;
std::vector<NodeType> SeedNodes; // An initial set of "start"
// nodes to be put in heap.
NodeType TargetNode; // "Goal" used for computing Heuristics. Not
// required if "getHeuristics" is not provided.
// If "stopSearch" is not provided, TargetNodeis
// is used to determine when to stop.
// Don't worry about the following now. This will be explained later.
SearchGraphDescriptorFunctionContainer<NodeType,CostType>*
func_container;
// Other variables and functions - constructor chooses a default
int hashBinSizeIncreaseStep; // optional. Default is 128.
// other internal use functions ...
// ...
};
Typically, for creating a graph, in your code you'll create an instance of this class and set the function pointers to functions defined by you, and set the values of "hashTableSize", "SeedNode" and "TargetNode". The members are quite self-explanatory by their name. A brief explanation of each:
- hashTableSize - This MUST be provided.
As discussed earlier, YAGSBPL maintains a hash table for keeping track of the nodes explored efficiently. This declares the size of the hash table. In other words, the value that (*getHashBin_fp) returns should lie between 0 and hashTableSize-1 (both inclusive). Otherwise a segmentation fault will be thrown. - getHashBin_fp - This MUST be provided.
Pointer to a function that maps nodes to hast bins in the hash table (i.e the hash function). Ideally this needs to be defined such that the nodes are distributed randomly and with uniform probability among all the bins. Please refer to http://en.wikipedia.org/wiki/Hash_function or any data-structure/programming book for more details.
IMPORTANT: getHashBin_fp should return an integer value between (including) 0 and hashTableSize-1. - isAccessible_fp - optional. All nodes will be considered accessible if not set.
Takes in a node and tells whether or not is accessible. TIP: If you are already testing accessibility inside getSuccessors_fp, do not set this for avoiding repated testing. - getSuccessors_fp - NOT optional for most planners.
Takes a node 'n', and returns a vector of successor nodes 's', along with the respective transition costs 'c'. 's' and 'c' should be of equal length. This function defines the connectivity of the directed graph and edge costs. - getPredecessors_fp - Not required if not required by planner. Weighted A* planner does not require it.
Provision is kept. But not used by weighted A* planner. So you need not worry about this if you are using the default planner. - getHeuristics_fp - optional. Zero heuristics is used if not set.
The heuristics function for A*. The heuristics will be set to 0 (i.e. Dijkstra's) if this function is not set. The function must return a value less than or equal to the actual cost between nodes 'n1' and 'n2'. - storePath_fp - optional.
Determined based on the node 'n', whether to store the path up to that node. Graph search will continue as usual. Only the path to 'n' will be stored intermediately. - stopSearch_fp - optional if "TargetNode" is provided.
Determines whether or not to stop the search process when the node 'n' has been expanded. This function also stores the path up-to 'n'. Note that the function can be used to define multiple possible stop nodes, whichever is reached earlier (e.g. the body may contain the statement "return (n==n1 || n==n2);".) - SeedNode and SeedNodes - Either SeedNode should be set, or at least one element should be there in the vector SeedNodes. isAccessible_fp should return true for the seed nodes.
The nodes to put in the "open" list at the start of the graph search. - TargetNode - optional if getHeuristics_fp is not set and stopSearch_fp is set.
Goal/target node used for computing Heuristics. Not required if "getHeuristics_fp" is not set. This does NOT, in general, determine when to stop search. However, if "stopSearch_fp" is not set, TargetNode is used to determine when to stop the search.
TROUBLESHOOT: If stopSearch_fp is not provided, make sure that the TargetNode is accessible and can be reached from a seed node. Planner will typically not check that at the beginning of planning.
Thus, in our "mygraphsearch.cpp" the following code may be present in the main function. Note the use of GenericSearchGraphDescriptor:
// Function declarations.
int getHashBin(myNode& n);
bool isAccessible(myNode& n);
double getHeuristics(myNode& n1, myNode& n2);
void getSuccessors(myNode& n, std::vector<myNode>* s,
std::vector<double>* c);
// Entry point
int main(int argc, char *argv[])
{
// Instance of GenericSearchGraphDescriptor.
GenericSearchGraphDescriptor<myNode,double> myGraph;
// We describe the graph, cost function, heuristics,
// and the start & goal in this block
// --------------------------------------------------
// Set the functions
myGraph.getHashBin_fp = &getHashBin;
myGraph.isAccessible_fp = &isAccessible;
myGraph.getSuccessors_fp = &getSuccessors;
myGraph.getHeuristics_fp = &getHeuristics;
// Set other variables
myGraph.hashTableSize = 212; // Should be greater than what
// "getHashBin" can return.
myGraph.hashBinSizeIncreaseStep = 512; // By default 128. Here
// we choose a higher value.
myNode tempNode;
tempNode.x = -150; tempNode.y = -150; // Start node
myGraph.SeedNode = tempNode;
tempNode.x = 150; tempNode.y = 150; // Goal node
myGraph.TargetNode = tempNode; // Since we did not give a value for
// 'stopSearch_fp', this will be used
// to determine when to stop.
// --------------------------------------------------
// Planning and other activities go here.
// ...
}
Where the functions getHashBin, isAccessible, getSuccessors and getHeuristics can be functions defined in the global scope as follows:
// Functions that describe the graph
int getHashBin(myNode& n)
{
// Use the absolute value of x coordinate as hash bin
// counter. Not a good choice though!
return ((int)fabs(n.x));
}
bool isAccessible(myNode& n)
{
// A 401x401 sized environment with (0,0) at center, and a circular
// obstacle of radius 100 centered at (0,0)
return ( n.x*n.x + n.y*n.y > 10000
&& n.x>=-200 && n.x<=200 && n.y>=-200 && n.y<=200 );
}
void getSuccessors(myNode& n,
std::vector<myNode>* s, std::vector<double>* c)
{
// Define a 8-nearest-neighbor connected graph
// This function needn't account for obstacles or size of environment.
// That is done by "isAccessible"
myNode tn;
s->clear(); c->clear(); // Planner is supposed to clear these.
// Still, for safety we clear it again.
for (int a=-1; a<=1; a++)
for (int b=-1; b<=1; b++) {
if (a==0 && b==0) continue;
tn.x = n.x + a;
tn.y = n.y + b;
s->push_back(tn);
c->push_back(sqrt((double)(a*a+b*b)));
}
}
double getHeuristics(myNode& n1, myNode& n2)
{
int dx = abs(n1.x - n2.x);
int dy = abs(n1.y - n2.y);
return (sqrt((double)(dx*dx + dy*dy))); // Euclidean distance as heuristics
}
Planning / Graph search:
Once the graph is created, using the default planner (A_star_planner) and retrieving the result is straight-forward. While retrieving the results, all the intermediately stored paths (triggered by 'storePath_fp') as well as the the last path (when 'stopSearch_fp' returned true). The last path will not be repeated if both 'storePath_fp' and 'stopSearch_fp' returned true for a node.
For planning using the provided A* planner, the template class and it's relevant members are as follows:
Snippet from YAGSBPL library:
class A_star_planner
{
// Set parameters. optional. - this function, if called,
// should be called before 'init'.
void setParams(
double eps=1.0, // Weighted A* search suboptimality
int heapKeyCt=20, // Number of 'keys' to maintain for heap
int progressDispInterval=10000 // Progress display interval
);
// Initializer and planner
void init( GenericSearchGraphDescriptor<NodeType,CostType> theEnv );
void plan(void);
// Planner output access:
// To be called after plan(), and before destruction of planner.
std::vector< std::vector< NodeType > > getPlannedPaths(void);
std::vector< CostType > getPlannedPathCosts(void);
std::vector< NodeType > getGoalNodes(void);
std::vector< GraphNode_p > getGoalGraphNodePointers(void);
// Retrieves pointers from the hash table
A_star_variables<CostType> getNodeInfo(NodeType n);
// Retrieves information about node 'n'.
// Clears the last plan result, but does not clean the hash table.
// Must be called after planner has been initialized ('init' function).
// Use this if you intend to re-plan with different start/goal.
void clearLastPlanAndInit
(GenericSearchGraphDescriptor<NodeType,CostType>* theEnv_p=NULL);
// Event handlers (described later)...
// Other members not relevant to user...
// ...
};
where the class A_star_variables has members CostType g, bool expanded, bool accessible and int seedLineage. Thus function getNodeInfo can be used to probe these information about an arbitrary node. int seedLineage gives the index of the seed from which the node was reached.
The following complete code for the main function explains the use of the planner and how to access the basic output:
int main(int argc, char *argv[])
{
GenericSearchGraphDescriptor<myNode,double> myGraph;
// We describe the graph, cost function, heuristics,
// and the start & goal in this block
// --------------------------------------------------
// Set the functions
myGraph.getHashBin_fp = &getHashBin;
myGraph.isAccessible_fp = &isAccessible;
myGraph.getSuccessors_fp = &getSuccessors;
myGraph.getHeuristics_fp = &getHeuristics;
// Set other variables
myGraph.hashTableSize = 212; // Should be greater than what
// "getHashBin" can return.
myGraph.hashBinSizeIncreaseStep = 512; // By default 128. Here
// we choose a higher value.
myNode tempNode;
tempNode.x = -150; tempNode.y = -150; // Start node
myGraph.SeedNode = tempNode;
tempNode.x = 150; tempNode.y = 150; // Goal node.
myGraph.TargetNode = tempNode; // Since we did not give a value for
// 'stopSearch_fp', this will be used
// to determine when to stop.
// --------------------------------------------------
// Planning
A_star_planner<myNode,double> planner;
planner.init(myGraph);
planner.plan();
// Retrieve the stored paths and print the coordinates.
std::vector< std::vector< myNode > > paths = planner.getPlannedPaths();
printf("Number of paths: %d\nPath coordinates: \n[ ", paths.size());
for (int a=0; a<paths[0].size(); a++)
printf("[%d, %d]; ", paths[0][a].x, paths[0][a].y);
printf(" ]\n\n");
}
 This illustration of progress of the A* search was created using event handlers and OpenCV library. See example program for details.
This illustration of progress of the A* search was created using event handlers and OpenCV library. See example program for details.Using event handlers
In v2.0 couple of event handlers were introduced. The event handlers are basically pointers to user-defined functions that the class A_star_planner maintains and calls every time the corresponding event is triggered during the planning process. The two types of events that can be handled:
- Node expansion: Triggered when a node 'n' gets expanded (placed in the closed list). Any of the following two members of
A_star_plannercan be set to handle this:
Snippet from YAGSBPL library:
class A_star_planner
{
// ...other members.
void (*event_NodeExpanded_g)(NodeType n, CostType gVal, CostType fVal, int seedLineage);
void (NodeType::*event_NodeExpanded_nm)(CostType gVal, CostType fVal, int seedLineage);
// other members...
}
- Successor updated: Triggered when a successor 'nn' of a node 'n' is updated (generated, placed on the open list, or g-value is updated). Any of the following two members of
A_star_plannercan be set to handle this:
Snippet from YAGSBPL library:
class A_star_planner
{
// ...other members.
void (*event_SuccUpdated_g)(NodeType n, NodeType nn, CostType edgeCost, CostType gVal, CostType fVal, int seedLineage);
void (NodeType::*event_SuccUpdated_nm)(NodeType nn, CostType edgeCost, CostType gVal, CostType fVal, int seedLineage);
// other members...
}
For more details on use of events refer to the example programs.
If you do not intend to use event handlers, you may choose to set the value of _YAGSBPL_A_STAR__HANDLE_EVENTS to 0 in A_star.h. This may give some marginal speed-up.
USING CLASS MEMBER FUNCTIONS
Say, you want to use pointers to member functions of a class for 'isAccessible_fp', 'getSuccessors_fp', etc. The following will fail since "bool (*)(NodeType& n)" and "bool (envDescriptionClass::*)(NodeType& n)" are of incompatable types:
// Includes and declaration of myNode goes here as usual.
// ....
class envDescriptionClass
{
public:
set(int xmin, int xmax, int ymin, int ymax)
{ Xmin=xmin; Xmax=xmax; Ymin=ymin; Ymax=ymax; };
// Member functions
bool isAccessible(myNode& n)
{ return( n.x>=Xmin && n.x<=Xmax && n.y>=Ymin && n.y<=Ymax ); }
// other members.
// ...
private:
int Xmin, Xmax, Ymin, Ymax;
};
int main(int argc, char *argv[])
{
envDescriptionClass envDescriptionClassInstance;
envDescriptionClassInstance.set( -200, 200, -200, 200 );
GenericSearchGraphDescriptor<myNode,double> myGraph;
// Set the functions that describe the graph
myGraph.isAccessible_fp = &envDescriptionClassInstance.isAccessible;
// This will FAIL!!
// No attempts (like type casting) to make this work will work.
// etc...
}
In order to be able to use class member functions, one of the following two approaches can be taken:
Creating a class that inherits and redefines virtual functions from "SearchGraphDescriptorFunctionContainer":
The preferred method is to derive the "envDescriptionClass" from YAGSBPL's "SearchGraphDescriptorFunctionContainer" and override the virtual functions declared in there. In YAGSBPL the following template class is declared:
Snippet from YAGSBPL library:
class SearchGraphDescriptorFunctionContainer
{
public:
virtual int getHashBin(NodeType& n);
virtual bool isAccessible(NodeType& n);
virtual void getSuccessors(NodeType& n, std::vector<NodeType>* s,
std::vector<CostType>* c);
virtual void getPredecessors(NodeType& n, std::vector<NodeType>* s,
std::vector<CostType>* c);
virtual CostType getHeuristics(NodeType& n1, NodeType& n2);
virtual bool storePath(NodeType& n);
virtual bool stopSearch(NodeType& n);
// other members ...
};
The following example illustrates how this can be used:
// Includes and declaration of myNode goes here as usual.
// ....
class envDescriptionClass : public SearchGraphDescriptorFunctionContainer<myNode,double>
{
public:
set(int xmin, int xmax, int ymin, int ymax)
{ Xmin=xmin; Xmax=xmax; Ymin=ymin; Ymax=ymax; };
// Virtual member functions derived from
// "SearchGraphDescriptorFunctionContainer" being overwritten...
// NOTE: The name of the functions are important here.
bool isAccessible(myNode& n)
{ return( n.x>=Xmin && n.x<=Xmax && n.y>=Ymin && n.y<=Ymax ); }
// other members.
// ...
private:
int Xmin, Xmax, Ymin, Ymax;
};
int main(int argc, char *argv[])
{
envDescriptionClass envDescriptionClassInstance;
envDescriptionClassInstance.set( -200, 200, -200, 200 );
// And in the instance of "GenericSearchGraphDescriptor",
// we set the member "func_container",
// instead of directly setting the function pointers
GenericSearchGraphDescriptor<myNode,double> myGraph;
myGraph.func_container = &envDescriptionClassInstance;
// This will WORK!! Automatic type casting.
// etc...
}
Using function container for direct pointers to member functions:
Alternatively, YAGSBPL also declares the following template class:
Snippet from YAGSBPL library:
class SearchGraphDescriptorFunctionPointerContainer
{
public:
ContainerClass* p;
int (ContainerClass::*getHashBin_fp)(NodeType& n);
bool (ContainerClass::*isAccessible_fp)(NodeType& n);
void (ContainerClass::*getSuccessors_fp)(NodeType& n,
std::vector<NodeType>* s, std::vector<CostType>* c);
void (ContainerClass::*getPredecessors_fp)(NodeType& n,
std::vector<NodeType>* s, std::vector<CostType>* c);
CostType (ContainerClass::*getHeuristics_fp)(NodeType& n1,
NodeType& n2);
bool (ContainerClass::*storePath_fp)(NodeType& n);
bool (ContainerClass::*stopSearch_fp)(NodeType& n);
// other members
// ...
};
This, along with the class "SearchGraphDescriptorFunctionContainer" (described later), can be used as follows for using class member functions.
// Includes and declaration of myNode goes here as usual.
// ....
class envDescriptionClass
{
public:
set(int xmin, int xmax, int ymin, int ymax)
{ Xmin=xmin; Xmax=xmax; Ymin=ymin; Ymax=ymax; };
// Member functions
bool isAccessible(myNode& n)
{ return( n.x>=Xmin && n.x<=Xmax && n.y>=Ymin && n.y<=Ymax ); }
// other members.
// ...
private:
int Xmin, Xmax, Ymin, Ymax;
};
int main(int argc, char *argv[])
{
envDescriptionClass envDescriptionClassInstance;
envDescriptionClassInstance.set( -200, 200, -200, 200 );
// We create an instance of
// "SearchGraphDescriptorFunctionPointerContainer"
SearchGraphDescriptorFunctionPointerContainer<myNode,double,envDescriptionClass>*
fun_pointer_container = new
SearchGraphDescriptorFunctionPointerContainer
<myNode,double,envDescriptionClass>;
// And set the pointers in it...
fun_pointer_container->p = &envDescriptionClassInstance; // This tells which
// instance to use.
fun_pointer_container->isAccessible_fp = &envDescriptionClass::isAccessible;
// likewise, set the other pointers to member functions...
// ...
// And in the instance of "GenericSearchGraphDescriptor",
// we set the member "func_container" after type casting,
// instead of directly setting the function pointers
GenericSearchGraphDescriptor<myNode,double> myGraph;
myGraph.func_container =
(SearchGraphDescriptorFunctionContainer<myNode,double>*)
fun_pointer_container;
// This will WORK!!
// NOTE: "SearchGraphDescriptorFunctionContainer"
// is a class defined in YAGSBPL library
// etc...
}
WRITING A PLANNER
The YAGSBPL comes with a default weighted A* planner. Setting the weight (eps) to 1.0 makes it standard A*, and setting the heuristics to 0 makes it Dijkstra. However these are definitely not the only planners that one can do away with. More advanced planners like D*, ARA*, etc. that can plan incrementally needs to be included. Writing a planner is also made quite simple in the YAGSBPL framework. YAGSBPL automatically creates and maintains the hash table and a heap. If you are interested in writing a planner, the best way to go about is to look into the code of the A start planner inside the "planners" folder of YAGSBPL. You'll hopefully find it quite short and precise so as to understand how it works and start writing your own planner in no time! The only point I would like to emphasize here is that it is always prudent to check if successors exist before calling "_getSuccessors", since the later is almost always a lot more expensive.
WRITING A GRAPH ENCAPSULATION
You may, if needed by your application, write an "encapsulation" on top of the "GenericSearchGraphDescriptor" class (e.g. derived from it). This may make your code much more structured and easy to write. No default encapsulation is provided since that will most likely be specific to your application.
INSTALLATION AND COMPILING
Since YAGSBPL is a template-based library, it cannot be compiled as an object file. All that needs to be done is include the header files in your C++ code. Thus, say the YAGSBPL library is located in the folder "/path/to/yagsbpl" (which contains the "yagsbpl_base.h" file and the "planners" folder), the following two things need to be done by you:
- In your code place the following includes:
#include "yagsbpl_base.h"
#include "planners/A_star.h" - When compiling your code have "/path/to/yagsbpl" in your include folder list. That is, compile with the option
-I/path/to/yagsbpl.
That's it!
SOME NOTES ON EFFICIENCY
One of the important design factor behind YAGSBPL was efficiency and speed. However much of the efficiency will also depend on how the user defines the graph node class and how efficiently the functions describing the graph structure are defined. Here are a few observations on profiling of the example code provided.
- The
operator==for the node class should be fast. Using integer coordinates instead of floating points will make it a lot faster. In the example above, declaring x and y of type double slows down the search almost 10 folds. So try to stick to integer coordinates. - The cost type, however, being integer does not give much advantage. A speed-up of ~10% was observed by changing double cost type to integer.
- It is also important to define a good hash function. Ideally it needs to be defined such that the nodes are distributed randomly and with uniform probability among all the hash bins. Please refer to http://en.wikipedia.org/wiki/Hash_function or any data-structure/programming book for more details on the purpose hash functions and how to design one.
- The implementation of the
getSuccessorsand how fast it runs determine much of the planning speed. The computation of the transition costs are often expensive. If, for example, the the transition costs are not function of the node 'n' itself, it may be a good idea to pre-compute them. For exqample, the implementation of the getSuccessors_fp in the example above could have been more efficient as follows:
// Includes and declaration of myNode and functions go here.
// ....
// fixed transition costs vector
std::vector<double> ConstCostVector;
int main(int argc, char *argv[])
{
// Defining the fixed transition costs
double SQRT2 = sqrt(2.0);
ConstCostVector.push_back(SQRT2); ConstCostVector.push_back(1.0);
ConstCostVector.push_back(SQRT2); ConstCostVector.push_back(1.0);
ConstCostVector.push_back(1.0); ConstCostVector.push_back(SQRT2);
ConstCostVector.push_back(1.0); ConstCostVector.push_back(SQRT2);
// initialization, graph description, etc. as before
// ...
myGraph.getSuccessors_fp = &getSuccessors;
// etc...
// Planning, etc...
}
// Other function definitions.
// ...
void getSuccessors(myNode& n,
std::vector<myNode>* s, std::vector<double>* c)
{
// Define a 8-nearest-neighbor connected graph
myNode tn;
s->clear(); c->clear();
for (int a=-1; a<=1; a++)
for (int b=-1; b<=1; b++) {
if (a==0 && b==0) continue;
tn.x = n.x + a;
tn.y = n.y + b;
s->push_back(tn);
}
*c = ConstCostVector; // Using the fixed cost vector
}
// other function definitions.
// ...
In the sample code (with less efficient implementation of 'getSuccessors'), running on a dual core processor with clock speed 2.1 GHz and 3GB RAM, the code could expand > 50,000 states in ~0.8 seconds, when it found the solution.
Finally, if you are done debugging your code, do not want to print progress of the planning process, and/or are not using event handlers, it may be a good idea to set _YAGSBPL_A_STAR__VIEW_PROGRESS and _YAGSBPL_A_STAR__HANDLE_EVENTS to 0 in A_star.h.
Since version 2.1 a binary heap implementation is used for priority list.
Keyed Heap
The keyed heap data-structure used by YAGSBPL is a little different from the conventional heap. Typically heaps are stored in arrays (the container) with each array element containing pointers to its children and parent in the heap. Random access to array elements is required for the insert operation since the potential parents can be located only by computed index. So replacing the array with a linked list is not possible. Thus, while the insert operation for the heap itself is of complexity O(log n), resizing the array and inserting element in the array is of complexity O(n). This makes the overall heap operations ~ O(log n) + O(n).
The keyed heap used by YAGSBPL is basically a linked list which is also a priority queue. So the pop operations for the heap is O(1) complexity. Besides the priority linked list itself, which does not allow random access to elements, a list of pointers to k key elements in the linked list is maintained, that point to elements in the linked list at approximate equal intervals of n/(k+1). Typically k is a modest number from 5 to 50. These keys are used for semi-random access, i.e. to find a good approximate location in the linked list from where to start the search for exact location to insert a new element. The keys are also updated every time a new element is inserted in the queue. This makes the insert operation ~ O(log k) + O(n/k).
The following approximate complexities apply operations on keyed heap used by YAGSBPL:
- pop (obtain smallest element and remove it from heap): ~ O(1)
- insert: ~ O(log k) + O(n/k)
- remove (remove from somewhere middle, given the pointer): ~ O(1)
In brief, keyed heap is just a priority linked list (i.e. linked list with all elements in order), along with a separately maintained and updated list of pointers to elements inside the linked list in order to help in efficiently finding the position in the linked list to insert new elements. The default value of k in YAGSBPL_base is 20, that works well for small to medium sized problems (heap size going up to ~10,000). For large problems one may want to increase the value. The value can be set using the planner's setParams function.